
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 파이썬 주식
- PolynomialFeatures
- 변동성돌파전략
- docker
- 백테스트
- backtest
- SQL
- ADP
- Crawling
- 파이썬
- Programmers
- Python
- lstm
- 주식
- randomforest
- sarima
- TimeSeries
- Quant
- 토익스피킹
- 비트코인
- 프로그래머스
- 실기
- 볼린저밴드
- 데이터분석
- hackerrank
- GridSearchCV
- 데이터분석전문가
- 빅데이터분석기사
- 파트5
- 코딩테스트
- Today
- Total
데이터 공부를 기록하는 공간
[QUANT] Auto Encoder 본문
출처 : (영상) https://www.youtube.com/watch?v=JTD_q4wuw_4
(코드) https://github.com/minsuk-heo/tf2/blob/master/jupyter_notebooks/04.AutoEncoder.ipynb
(내용) https://velog.io/@cha-suyeon/%EC%98%A4%ED%86%A0%EC%9D%B8%EC%BD%94%EB%8D%94Autoencoder
입력층보다 적은 수의 뉴런를 가진 은닉층을 중간에 넣어 줌으로써 차원을 줄입니다.
학습을 통해 축소 및 복원하는 과정을 통해 입력 데이터의 특징을 효율적으로 응축한 새로운 출력이 만드는 프로세스
오토인코더(Autoencoder)는 어떤 지도 없이도(즉, 레이블되어 있지 않은 훈련 데이터를 사용하여) 잠재 표현(latent representation) 또는 코딩(coding)이라 부르는 입력 데이터의 밀집 표현을 학습할 수 있는 인공 신경망입니다.
오토인코더는 차원 축소, 특성 추출, 비지도 사전훈련 방법과 이를 생성 모델로 사용하는 방법 등이 있습니다.
- 시각화 유용 : 입력보다 낮은 차원으로 축소
- 비지도 사전훈련에 활용 : 강력한 특성 추출기 처럼 작동가능
- 새로운 데이터 생성 : 일부 오토인코더에 해당. 생성모델(generative model)
- 예) 얼굴사진으로 새로운 얼굴을 생성할 수 있음
- 잠재벡터(잠재표현)의 크기를 제한하거나 입력에 잡음을 추가하여 원본 입력을 복원하도록 훈련
- 단순히 입력을 출력으로 바로 복사하지 못하게 막아, 데이터를 효율적으로 표현하는 방법을 배우게 만듬
1. Auto Encoder Basic

Auto Encoder의 기본 디자인.
Input Vector의 차원을 줄여주고, 다시 Output Vector를 Input Vector의 차원으로 늘려줌

2. encoder (input , reduce dimensions)
숫자 1을 어떻게 인식할지 살펴봅니다.

숫자 1을 보여주는 이미지를 매트릭스(행렬)로 나타내고,
이를 Flatten 해줍니다. (1차원화)
그다음 INPUT으로는 1차원 벡터의 위치에 해당하는 RGB 값을 넣어줍니다. (0~255, 0은 검정, 255는 하얀색)
3. Latent Vector


4. decoder

다시 Input vector의 차원으로 복귀합니다.
✔ 최적화(Optimizer) : Minimize loss (input과 decoder 결과 차이)
5. Import Library and Load data (MNIST)
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import numpy as np
from IPython.display import Image
# in order to always get the same result
tf.random.set_seed(1)
np.random.seed(1)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# select only 300 test dataset
x_test = x_test[:300]
y_test = y_test[:300]
# flatten : 28*28 > 784
x_train = x_train.reshape(x_train.shape[0], 784)
x_test = x_test.reshape(300, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# normalize
gray_scale = 255
x_train /= gray_scale
x_test /= gray_scale
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)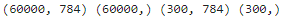
차원을 줄여줍니다. (Flatten)
0~255의 데이터를 0~1사이로 scaling합니다. (normalize)
6. AutoEncoder Modeling
# Mnist input 28 rows * 28 rows = 784pixels
input_img = Input(shape=(784,))
#encoder
encoder1 = Dense(512, activation='sigmoid')(input_img)
encoder2 = Dense(3, activation='sigmoid')(encoder1)
#decoder
decoder1 = Dense(512, activation='sigmoid')(encoder2)
decoder2 = Dense(784, activation='sigmoid')(decoder1)
# thid model maps an input to its reconstruction
autoencoder = Model(inputs=input_img, outputs=decoder2)
autoencoder.summary()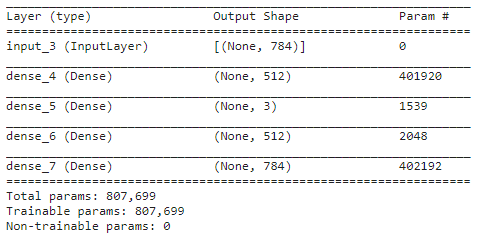
[사이즈]
Input Vector 784
Latent Vector : 3
Output Vector : 784
# autoencoder는 학습 시 X,y가 같다.
# 목적함수가 input을 인코딩, 디코딩을 거친 output과 일치해야하므로
# adam을 쓰고, crossentropy를 줄여나간다.
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=5,
batch_size=32,
shuffle=True,
validation_data=(x_test, x_test))
7. Latent Vector(encoder) 3D Visualization
#############################
##### get latent Vector #####
#############################
# create encoder model
encoder = Model(inputs=input_img, outputs=encoder2)
# get latent vector for visualization
latent_vector = encoder.predict(x_test) # latent vector는 encoder의 Output# visualizer in 3D plot
from pylab import rcParams
from mpl_toolkits.mplot3d import Axes3D
rcParams['figure.figsize'] = 10,8
fig = plt.figure(1)
ax = Axes3D(fig)
xs = latent_vector[:,0]
ys = latent_vector[:,1]
zs = latent_vector[:,2]
color=['red','green','blue','lime','white','pink','aqua','violet','gold','coral'] # 10개
for x, y, z, label in zip(xs, ys, zs, y_test):
c = color[int(label)]
ax.text(x,y,z,label, backgroundcolor=c)
ax.set_xlim(xs.min(), xs.max())
ax.set_ylim(ys.min(), ys.max())
ax.set_zlim(zs.min(), zs.max())
plt.show()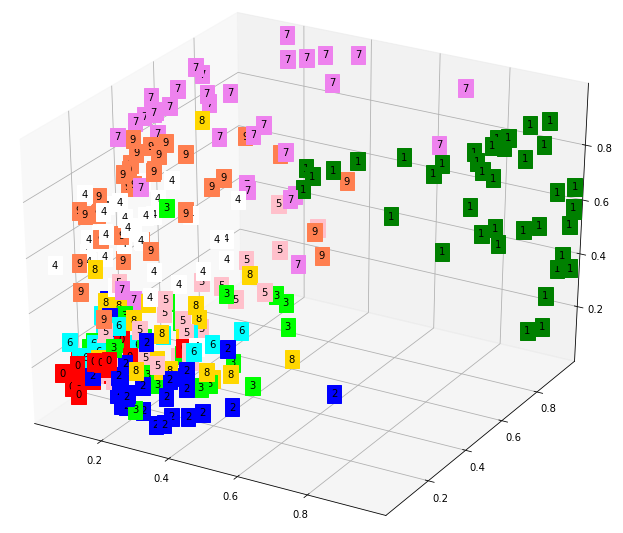
Latent벡터를 3차원으로 표현해서
결과값에 따라 클러스터링 된 것을 볼 수 있습니다.
8. Decoder and Visualization
# MINIST Original and Reconstructed Images Visualization
encoded_input = Input(shape=(3,))
decoder_layer1 = autoencoder.layers[-2]
decoder_layer2 = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input,
outputs=decoder_layer2(decoder_layer1(encoded_input)))
# get decoder outpu to visualize reconstructed image
reconstructed_imgs = decoder.predict(latent_vector)n = 10
plt.figure(figsize=(20,4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i+1)
plt.imshow(x_test[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstructed image
ax = plt.subplot(2, n, i+1+n)
plt.imshow(reconstructed_imgs[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)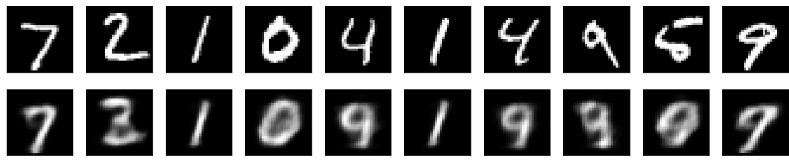
위가 original, 아래가 reconstructed image
완벽하진 않지만 비슷하게 복원된 것을 확인할 수 있습니다.
'STOCK > QUANT' 카테고리의 다른 글
| [QUANT] multi LSTM - ets,coal,gas (0) | 2022.06.26 |
|---|---|
| [QUANT] Asset Allocation (0) | 2022.06.12 |
| [QUANT] 백테스트 - VAA 전략 (0) | 2022.06.12 |
| [QUANT] INVESTING.COM (0) | 2022.06.12 |
| [QUANT] 멀티팩터모델을 활용한 시장국면 진단 (0) | 2022.06.10 |



