
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- randomforest
- PolynomialFeatures
- 빅데이터분석기사
- 비트코인
- Programmers
- 백테스트
- 실기
- 파이썬
- 프로그래머스
- 변동성돌파전략
- lstm
- Crawling
- hackerrank
- 데이터분석
- 파트5
- 파이썬 주식
- Quant
- 주식
- Python
- ADP
- TimeSeries
- GridSearchCV
- sarima
- docker
- SQL
- 데이터분석전문가
- backtest
- 볼린저밴드
- 토익스피킹
- 코딩테스트
Archives
- Today
- Total
데이터 공부를 기록하는 공간
[QUANT] Asset Allocation 본문
샤프지수가 높은 자산배분 얻어오려면 수익률을 포기해야할까
1. 라이브러리 및 데이터 불러오기 !
# 필요 라이브러리 import
import pandas_datareader as pdr
import pandas as pd
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
import seaborn as sns
import math
import quantstats as qs
from tqdm import tqdm
import numpy as np
import warnings
warnings.filterwarnings('ignore')
pd.options.display.float_format = '{:.4f}'.formatstocks = ['SPY','GLD','NDAQ','TIP','SHY','EEM']
# extend pandas functionality with metrics, etc.
qs.extend_pandas()
# fetch the daily returns for a stock
df = pd.DataFrame()
for i in tqdm(stocks):
df[i] = qs.utils.download_returns(i)
df.head()

종목은 총 6가지를 살펴본다.
1993년에는 SPY 데이터 밖에 없었다.
2. 종목들의 수익률을 그려서 살펴봅시다
df = df.dropna()
data = df.copy()
np.log(data+1).cumsum().plot(figsize=(20,5), title='log return')
로그수익률이 이렇다. 나스닥의 변동성은 큰대신 수익률도 높다.
3. 반복문으로 포트폴리오 가중치를 정해서 평가해봅시다
data = df.dropna().copy()
port_ret = []
port_sharpe = []
port_mdd = []
port_weights = []
# 시나리오
for _ in tqdm(range(3000)):
weights = np.random.random(len(stocks))
weights /= np.sum(weights)
rets = (data*weights).sum(axis=1) #dataframe 반환
ret = ((1+rets).cumprod()-1)[-1]
sharpe = rets.sharpe()
mdd = rets.max_drawdown()
port_weights.append(weights)
port_ret.append(ret)
port_sharpe.append(sharpe)
port_mdd.append(mdd)
portfolio = {"Returns": port_ret, "MDD":port_mdd, "Sharpe":port_sharpe}
for i, s in enumerate(stocks):
portfolio[s] = [weight[i] for weight in port_weights]
# dataframe
temp = pd.DataFrame(portfolio)
temp = temp[['Returns','MDD','Sharpe'] + [s for s in stocks]]
#
max_sharpe = temp.loc[temp["Sharpe"] == temp['Sharpe'].max()]
min_risk = temp.loc[temp['MDD']==temp['MDD'].max()]
# graph
temp.plot.scatter(x="MDD", y="Returns", c='Sharpe', cmap='viridis', edgecolors='k', figsize=(11,7), grid=True)
plt.scatter(x=max_sharpe['MDD'], y=max_sharpe['Returns'], c='r', marker='*', s=300)
plt.scatter(x=min_risk['MDD'], y=min_risk['Returns'], c='r', marker='X', s=200)
plt.title("Portfolio Optimization")
plt.xlabel("MDD")
plt.ylabel("Expected Returns")
plt.show()
가로축은 MDD
세로축은 수익률
색깔은 샤프지수다.
max_ret = temp.loc[temp['Returns']==temp['Returns'].max()]
max_ret
3000가지 시나리오 중 357번 시나리오의 수익률이 1400%로 가장 높았다.
다만 MDD도 54%로 꽤 높은 편이다.
나스닥 비중이 67%이다.
max_sharpe
2214번 시나리오는 수익률이 143%이지만 MDD는 12%고, 샤프지수는 1.13으로 가장 높다.
TIP > SHY > GOLD 순으로 비중이 높다.
4. 베스트 시나리오(샤프지수)로 Quantstats 리포트 뽑아봅시다
best_weights = max_sharpe[max_sharpe.columns[3:]]
best_rets = (data*best_weights.values.tolist()[0]).sum(axis=1) #dataframe 반환
best_retsquanststats에 넣어주기 위해 샤프지수가 가장 높은 값을 베스트 시나리오로 정하고 수익률을 데이터프레임으로 만들어준다.
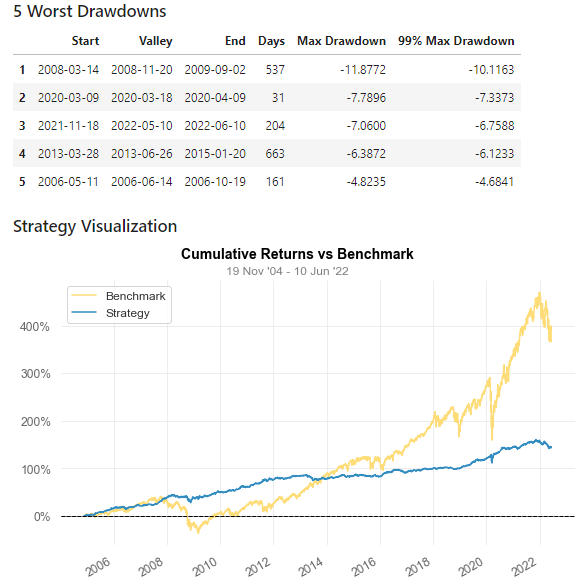
qs.reports.full(best_rets, "SPY")




'STOCK > QUANT' 카테고리의 다른 글
| [QUANT] multi LSTM - ets,coal,gas (0) | 2022.06.26 |
|---|---|
| [QUANT] Auto Encoder (0) | 2022.06.25 |
| [QUANT] 백테스트 - VAA 전략 (0) | 2022.06.12 |
| [QUANT] INVESTING.COM (0) | 2022.06.12 |
| [QUANT] 멀티팩터모델을 활용한 시장국면 진단 (0) | 2022.06.10 |
'STOCK/QUANT' Related Articles
more




Comments