
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- PolynomialFeatures
- 빅데이터분석기사
- Python
- 데이터분석
- Programmers
- randomforest
- 데이터분석전문가
- 실기
- lstm
- 파이썬 주식
- docker
- 볼린저밴드
- 변동성돌파전략
- ADP
- 파트5
- 코딩테스트
- SQL
- backtest
- Quant
- hackerrank
- Crawling
- 토익스피킹
- 백테스트
- sarima
- 주식
- 프로그래머스
- TimeSeries
- GridSearchCV
- 비트코인
- 파이썬
Archives
- Today
- Total
데이터 공부를 기록하는 공간
[QUANT] 백테스트 - VAA 전략 본문
가장 최우선으로 있던 VAA전략에 대해서 살펴보겠습니다.
게으른 퀀트님의 글을 따라 써 보았습니다.
좋은 글이라 생각되서 글 작성 연습입니다.
원본글의 출처는 아래와 같습니다.
https://lazyquant.tistory.com/101
1. 라이브러리 import 및 메타데이터 세팅
# 필요 라이브러리 import
import pandas_datareader as pdr
import pandas as pd
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
import seaborn as sns
import math
import quantstats as qs
# pandas 설정 및 메타데이터 세팅
pd.options.display.float_format = '{:.4f}'.format
pd.set_option('display.max_columns', None)
start_day = datetime(2008,1,1) # 시작일
end_day = datetime(2022,6,12) # 종료일
# RU : Risky Universe
# CU : Cash Universe
# BU : Benchmark Universe
RU = ['SPY','VEA','EEM','AGG']
CU = ['LQD','SHY','IEF']
BU = ['^GSPC','^IXIC','^KS11','^KQ11'] # S&P500 지수, 나스닥 지수, 코스피 지수, 코스닥 지수3가지의 자산군으로 나누었습니다. RU(공격자산) , CU(방어자산), BU(벤치마크)
2. 데이터 추출
# 데이터 추출 함수
def get_price_data(RU, CU, BU):
df_RCU = pd.DataFrame(columns=RU+CU)
df_BU = pd.DataFrame(columns=BU)
for ticker in RU + CU:
df_RCU[ticker] = pdr.get_data_yahoo(ticker, start_day - timedelta(days=365), end_day)['Adj Close']
for ticker in BU:
df_BU[ticker] = pdr.get_data_yahoo(ticker, start_day - timedelta(days=365), end_day)['Adj Close']
return df_RCU, df_BUpandas_datareader의 get_data_yahoo 메소드를 활용하여 데이터를 불러옵니다.
- timedelta(days=365) 를 해주는 이유는 모멘텀 계산을 위하여 12개월 전까지의 주가가 필요하기 때문입니다.
# 각 자산 군의 데이터 추출
df_RCU, df_BU = get_price_data(RU, CU, BU)
df_RCU.head(5)
2007년에는 VEA가 없었을 때라 주가가 표기되지 않습니다. VEA가 상장 될때 까지 RU는 SPY, EEM, AGG 3가지로만 가져가게 됩니다. 코드 결과에는 크게 영향을 주지 않으니 그대로 진행하겠습니다.
3. 모멘텀 지수 계산
# 모멘텀 지수 계산 함수
def get_momentum(x):
temp_list = [0 for i in range(len(x.index))]
momentum = pd.Series(temp_list, index=x.index)
try:
before1 = df_RCU[x.name-timedelta(days=35):x.name-timedelta(days=30)].iloc[-1][RU+CU]
before3 = df_RCU[x.name-timedelta(days=95):x.name-timedelta(days=90)].iloc[-1][RU+CU]
before6 = df_RCU[x.name-timedelta(days=185):x.name-timedelta(days=180)].iloc[-1][RU+CU]
before12 = df_RCU[x.name-timedelta(days=370):x.name-timedelta(days=365)].iloc[-1][RU+CU]
momentum = 12 * (x / before1 - 1) + 4 * (x / before3 - 1) + 2 * (x / before6 - 1) + (x / before12 - 1)
except Exception as e:
#print("Error : ", str(e))
pass
return momentumDataFrame의 한 컬럼(한 자산)씩 계산하는 함수입니다. 코드를 보면 복잡하지는 않습니다.
- x는 현재의 주가이고, 모멘텀 지수를 계산할 지난 주가를 각각 before1, before3, before6, before12로 구합니다.
- x.name은 DatFrame의 인덱스 중 날짜를 의미합니다.
- try를 사용하는 이유는 35일전, ... , 370일전 등의 데이터가 없으면 오류가 발생하기 때문입니다.
- 실제 필요날짜보다 5일 정도 데이터를 조회해서 가장 마지막 데이터를 iloc[-1]을 사용하여 가장 마지막날의 주가만 사용합니다. 주말, 공휴일 등 휴장일일 수 있기 때문입니다.
# 각 자산별 모멘텀 지수 계산
mom_col_list = [col+'_M' for col in df_RCU[RU+CU].columns]
df_RCU[mom_col_list] = df_RCU[RU+CU].apply(lambda x: get_momentum(x), axis=1)
df_RCU[mom_col_list].tail(5)
4. 백테스트기간 데이터 추출
모멘텀 스코어를 계산했으니, 백테스트를 진행할 구간의 데이터만 다시 뽑아냅니다.
모멘텀 스코어가 계산되지 않은 최초의 1년치 데이터는 제외합니다.
그리고 월말에만 리밸런싱을 진행한다고 가정하여 월말 데이터만 남깁니다.
# 백테스트할 기간 데이터 추출
df_RCU = df_RCU[start_day:end_day]
# 매월 말일 데이터만 추출(리밸런싱에 사용)
df_RCU = df_RCU.resample(rule='M').last()
df_RCU.tail(5)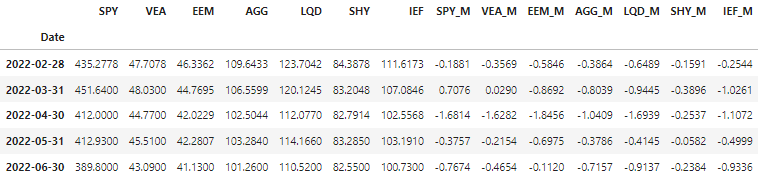
5. VAA 전략기준에 맞춘 자산 선택
# VAA 전략 기준에 맞춰 자산 선택
def select_asset(x):
asset = pd.Series([0,0], index=['ASSET','PRICE'])
# 공격 자산이 모두 0이상이면, 공격 자산 중 최고 모멘텀 자산 선정
if x['SPY_M'] > 0 and x['VEA_M'] > 0 and x['EEM_M'] > 0 and x['AGG_M'] > 0:
max_momentum = max(x['SPY_M'],x['VEA_M'],x['EEM_M'],x['AGG_M'])
# 공격 자산 중 하나라도 0이하라면, 방어 자산 중 최고 모멘텀 자산 선정
else :
max_momentum = max(x['LQD_M'],x['SHY_M'],x['IEF_M'])
asset['ASSET'] = x[x == max_momentum].index[0][:3]
asset['PRICE'] = x[asset['ASSET']]
return asset# 매월 선택할 자산과 가격
df_RCU[['ASSET','PRICE']] = df_RCU.apply(lambda x: select_asset(x), axis=1)
df_RCU
6. 각 자산 및 VAA 전략 수익률 계산
# 각 자산별 수익률 계산
profit_col_list = [col+'_P' for col in df_RCU[RU+CU].columns]
df_RCU[profit_col_list] = df_RCU[RU+CU].pct_change()
df_RCUpct_change() 함수를 활용하여 전체 자산군의 지난달 대비 수익률을 계산합니다.

# 매월 수익률 & 누적 수익률 계산
df_RCU['PROFIT'] = 0
df_RCU['PROFIT_ACC'] = 0
df_RCU['LOG_PROFIT'] = 0
df_RCU['LOG_PROFIT_ACC'] = 0
for i in range(len(df_RCU)):
profit = 0
log_profit = 0
if i != 0:
profit = df_RCU[df_RCU.iloc[i-1]['ASSET'] + '_P'].iloc[i]
log_profit = math.log(profit+1)
df_RCU.loc[df_RCU.index[i], 'PROFIT'] = profit
df_RCU.loc[df_RCU.index[i], 'PROFIT_ACC'] = (1+df_RCU.loc[df_RCU.index[i-1], 'PROFIT_ACC'])*(1+profit)-1
df_RCU.loc[df_RCU.index[i], 'LOG_PROFIT'] = log_profit
df_RCU.loc[df_RCU.index[i], 'LOG_PROFIT_ACC'] = df_RCU.loc[df_RCU.index[i-1], 'LOG_PROFIT_ACC'] + log_profit
# 백분율을 %로 표기
df_RCU[['PROFIT', 'PROFIT_ACC', 'LOG_PROFIT','LOG_PROFIT_ACC']] = df_RCU[['PROFIT', 'PROFIT_ACC', 'LOG_PROFIT','LOG_PROFIT_ACC']] * 100
df_RCU[profit_col_list] = df_RCU[profit_col_list] * 100df_RCU.tail(5)
7. quantstats 기본 리포트
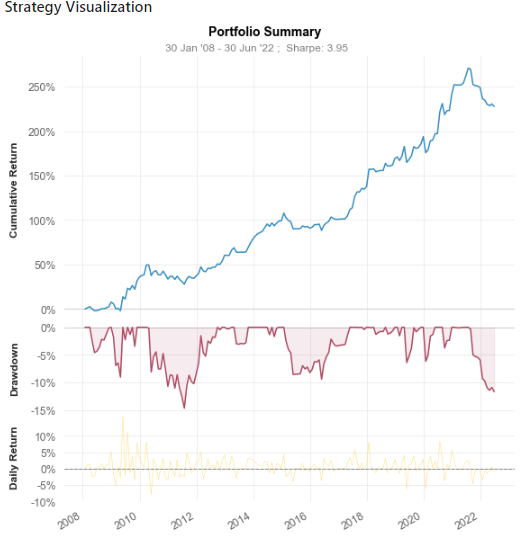
qs.reports.basic(df_RCU['PROFIT']/100, benchmark='^GSPC') #^GSPC : S&P500quantstats.report에는 월별 수익률 데이터를 넣어줍니다.
벤치마크로는 S&P500을 넣어줍니다.


'STOCK > QUANT' 카테고리의 다른 글
| [QUANT] multi LSTM - ets,coal,gas (0) | 2022.06.26 |
|---|---|
| [QUANT] Auto Encoder (0) | 2022.06.25 |
| [QUANT] Asset Allocation (0) | 2022.06.12 |
| [QUANT] INVESTING.COM (0) | 2022.06.12 |
| [QUANT] 멀티팩터모델을 활용한 시장국면 진단 (0) | 2022.06.10 |
'STOCK/QUANT' Related Articles
more




Comments