
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 백테스트
- TimeSeries
- 주식
- 파이썬 주식
- 토익스피킹
- Programmers
- hackerrank
- 데이터분석전문가
- Crawling
- 볼린저밴드
- PolynomialFeatures
- randomforest
- 데이터분석
- GridSearchCV
- 프로그래머스
- Python
- backtest
- docker
- 코딩테스트
- 실기
- 변동성돌파전략
- SQL
- sarima
- 비트코인
- 파이썬
- lstm
- 파트5
- ADP
- 빅데이터분석기사
- Quant
Archives
- Today
- Total
데이터 공부를 기록하는 공간
빅데이터분서기사 실기 - XGBoostRegressor 본문
import pandas as pd
import numpy as np
train = pd.read_csv("./house-prices-advanced-regression-techniques/train.csv")
test = pd.read_csv("./house-prices-advanced-regression-techniques/test.csv")
y_train = train['SalePrice']
# null data 확인
ex_cols = train.isnull().sum().sort_values(ascending=False).head(6).index.tolist()
# null data drop
train.drop(ex_cols,axis=1, inplace=True)
train.drop('Id',axis=1,inplace=True)
test.drop(ex_cols,axis=1, inplace=True)
test.drop('Id',axis=1,inplace=True)
train.drop("SalePrice", axis=1, inplace=True)
# feature
obj_cols = train.select_dtypes(include='object').columns.tolist()
num_cols = [x for x in train.columns.tolist() if x not in obj_cols]
for col in obj_cols:
train[col].fillna(train[col].value_counts().index[0], inplace=True) # 최빈값
test[col].fillna(train[col].value_counts().index[0], inplace=True) # 최빈값
for col in num_cols:
train[col].fillna(train[col].mean(), inplace=True)
test[col].fillna(train[col].mean(), inplace=True)
print(train.shape)
#print(train.isnull().sum().sort_values(ascending=False).head(20))
# 레이블인코딩, minmax scaler
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
le = LabelEncoder()
mm = MinMaxScaler()
for col in obj_cols:
le.fit(train[col])
train[col] = le.transform(train[col])
test[col] = le.transform(test[col])
for col in num_cols:
mm.fit(np.array(train[col]).reshape(-1,1))
train[col] = mm.transform(np.array(train[col]).reshape(-1,1))
test[col] = mm.transform(np.array(test[col]).reshape(-1,1))
# train,valid set 분리
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(train, y_train, test_size=0.3)
print(X_train.shape, X_valid.shape, y_train.shape, y_valid.shape)
# xgboost, 평가
import xgboost as xgb
from sklearn.metrics import r2_score
xgb_model = xgb.XGBRegressor(n_estimators=300, max_depth=3, learning_rate=0.05, n_jobs=-1)
xgb_model.fit(X_train, y_train, eval_set = [(X_valid, y_valid)], early_stopping_rounds=30, verbose=0)
# 결과해석
pred = xgb_model.predict(X_valid)
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(1,2, figsize=(12,4))
ax1.scatter(y_valid, pred)
ax1.set_xlabel("y_valid")
ax1.set_ylabel("prediction")
ax2.scatter(range(y_valid.shape[0]), pred-y_valid, label='pred-y_valid')
ax2.legend()
ax1.set_title("XGBOOST REGRESSOR")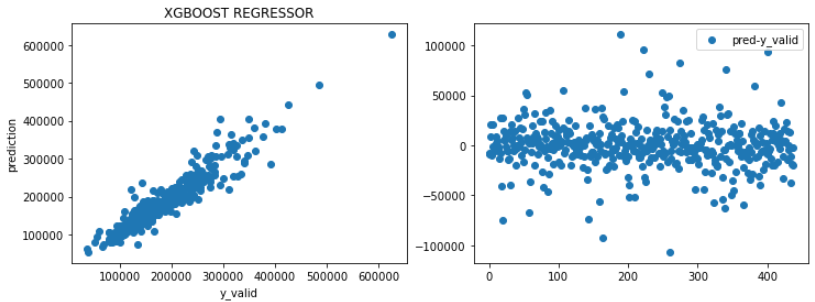
'STUDY > ADP, 빅데이터분석기사' 카테고리의 다른 글
| adp, 빅데이터분석 기사 합격 (0) | 2021.08.08 |
|---|---|
| 빅데이터분석기사 실기 - 분류 (0) | 2021.06.13 |
| 빅데이터분석기사실기-XGBOOST 분류 (0) | 2021.06.06 |
| 빅데이터분석기사 실기 예제 - 작업형#1 (0) | 2021.06.05 |
| [arima] smp2 (0) | 2021.03.21 |
'STUDY/ADP, 빅데이터분석기사' Related Articles
more



Comments