
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Quant
- TimeSeries
- 백테스트
- 데이터분석전문가
- hackerrank
- PolynomialFeatures
- 빅데이터분석기사
- SQL
- 파트5
- sarima
- 볼린저밴드
- 파이썬
- backtest
- 프로그래머스
- ADP
- randomforest
- lstm
- 토익스피킹
- 데이터분석
- Crawling
- 코딩테스트
- 파이썬 주식
- Programmers
- 비트코인
- docker
- 실기
- 변동성돌파전략
- GridSearchCV
- 주식
- Python
Archives
- Today
- Total
데이터 공부를 기록하는 공간
빅데이터분석기사실기-XGBOOST 분류 본문
XGBOOST를 활용해서 예제문제를 풀어보려고 한다.
1. 데이터불러오기~ 데이터전처리
2. 싸이킷런 래퍼 + 그리드서치
3. 파이썬 래퍼
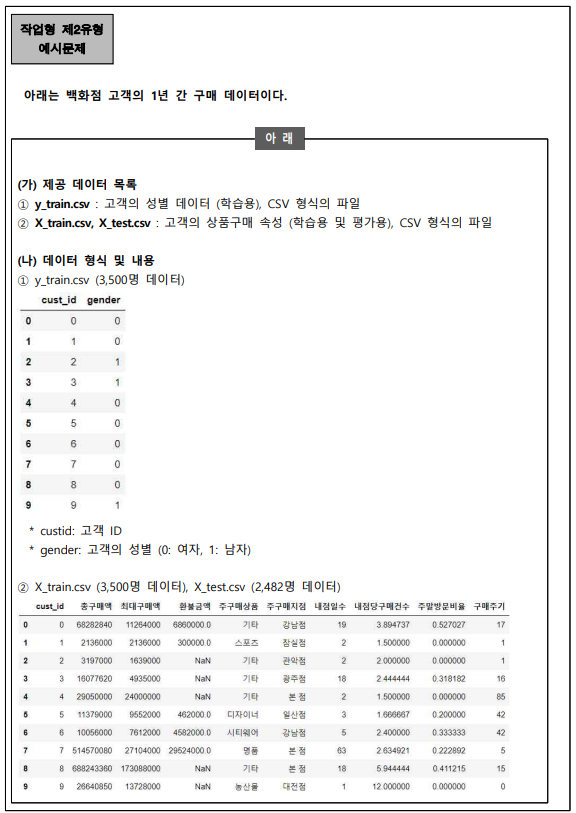

1. 데이터불러오기~데이터전처리
# 출력을 원하실 경우 print() 활용
# 예) print(df.head())
# 답안 제출 예시
# 수험번호.csv 생성
# DataFrame.to_csv("0000.csv", index=False)
######## 1. 라이브러리 임포트
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
######## 2. 데이터불러오기/ 데이터 전처리
X_train = pd.read_csv("./data/X_train.csv",encoding='cp949')
X_test = pd.read_csv("./data/X_test.csv",encoding='cp949')
y_train = pd.read_csv("./data/y_train.csv",encoding='cp949')
X = pd.concat([X_train, X_test],axis=0) # 합치기
print(X_train.shape, X_test.shape, X.shape)
#전처리
# null 데이터 처리
X.drop('cust_id',axis=1, inplace=True) # 고객 id drop
y_train.drop('cust_id',axis=1, inplace=True) # 고객 id drop
X['환불금액'] = X['환불금액'].fillna(0) # null data 0으로 채워주기
# 레이블인코딩, 정규화
object_cols = X.select_dtypes(include='object').columns
numeric_cols = [x for x in X.columns if x not in object_cols]
le = LabelEncoder()
for col in object_cols:
X[col] = le.fit_transform(X[col])
ss = StandardScaler()
for col in numeric_cols:
X[col] = ss.fit_transform(np.array(X[col]).reshape(-1,1))
# 학습/테스트 데이터 분리
X_train = X.iloc[:3500,:]
X_test = X.iloc[3500:,:]
# 학습용/검증용 데이터 분리
X1, X2, y1, y2 = train_test_split(X_train, y_train, test_size=0.3, random_state=37, shuffle=True)
print(X1.shape, X2.shape, y1.shape, y2.shape)2. 싸이킷런 래퍼
from sklearn.metrics import roc_auc_score, accuracy_score
xgb_model = xgb.XGBClassifier(n_estimators=500, max_depth=5, learning_rate=0.2, objective='binary:logistic')
xgb_model.fit(X1, y1, early_stopping_rounds=50, eval_metric='auc', eval_set=[(X2,y2)], verbose=False)
pred = xgb_model.predict(X2)
auc = roc_auc_score(y2,pred)
acc = accuracy_score(y2, pred)
print("roc_auc score : ", auc)
print("accuracy score : ", acc)
results = pd.DataFrame(xgb_model.predict_proba(X_test))[1]
# results.to_csv("~~~.csv",index=False) # 저장2-2 싸이킷런 + 그리드서치
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators':[100,300,700],
'learning_rate':[0.01, 0.1, 0.3],
'max_depth':[3,7,12]
}
gridsearch = GridSearchCV(xgb_model, param_grid = param_grid, cv=5, scoring='accuracy', n_jobs=-1, verbose=1)
bestmodel = gridsearch.fit(X_train, y_train)
n_estimators = bestmodel.best_estimator_.get_params()['n_estimators']
learning_rate = bestmodel.best_estimator_.get_params()['learning_rate']
max_depth = bestmodel.best_estimator_.get_params()['max_depth']
print(n_estimators, learning_rate, max_depth)
xgb_model = xgb.XGBClassifier(n_estimators=n_estimators, learning_rate=learning_rate, max_depth=max_depth)
pred = xgb_model.predict_proba(X2)
auc = roc_auc_score(y2,pred)
acc = accuracy_score(y2, pred)
print("roc_auc score : ", auc)
print("accuracy score : ", acc)
results = pd.DataFrame(xgb_model.predict_proba(X_test))[1]
# results.to_csv("~~~.csv",index=False) # 저장▶ accuracy score가 0.64 ▶ 0.648로 소폭 상승했다.
▶ 낮은 정확도로 데이터 전처리가 더 필요해 보인다.
3. 파이썬래퍼
import xgboost as xgb ## XGBoost 불러오기
from xgboost import plot_importance ## Feature Importance를 불러오기 위함
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
from sklearn.metrics import confusion_matrix, f1_score, roc_auc_score
# 넘파이 형태의 학습 데이터 세트와 테스트 데이터를 DMatrix로 변환하는 예제
dtrain = xgb.DMatrix(data=X1, label = y1)
dtest = xgb.DMatrix(data=X2, label=y2)
# max_depth = 3, 학습률은 0.1, 예제가 이진분류이므로 목적함수(objective)는 binary:logistic(이진 로지스틱)
# 오류함수의 평가성능지표는 auc
# 부스팅 반복횟수는 300
# 조기중단을 위한 최소 반복횟수는 100
params = {'max_depth' : 3,
'eta' : 0.1,
'objective' : 'binary:logistic',
'eval_metric' : 'auc',
'early_stoppings' : 100 }
num_rounds = 300
# train 데이터 세트는 'train', evaluation(test) 데이터 세트는 'eval' 로 명기
wlist = [(dtrain, 'train'), (dtest,'eval')]
# 하이퍼 파라미터와 early stopping 파라미터를 train() 함수의 파라미터로 전달
xgb_model = xgb.train(params = params, dtrain=dtrain, num_boost_round=num_rounds, evals=wlist)'STUDY > ADP, 빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 실기 - 분류 (0) | 2021.06.13 |
|---|---|
| 빅데이터분서기사 실기 - XGBoostRegressor (0) | 2021.06.06 |
| 빅데이터분석기사 실기 예제 - 작업형#1 (0) | 2021.06.05 |
| [arima] smp2 (0) | 2021.03.21 |
| [arima] smp (0) | 2021.03.21 |
'STUDY/ADP, 빅데이터분석기사' Related Articles
more



Comments