
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- randomforest
- 데이터분석
- 프로그래머스
- docker
- Python
- Quant
- lstm
- 실기
- PolynomialFeatures
- GridSearchCV
- 파트5
- 데이터분석전문가
- 토익스피킹
- 파이썬
- 비트코인
- 코딩테스트
- SQL
- ADP
- hackerrank
- 변동성돌파전략
- 주식
- 백테스트
- 볼린저밴드
- TimeSeries
- Programmers
- backtest
- Crawling
- sarima
- 빅데이터분석기사
- 파이썬 주식
Archives
- Today
- Total
데이터 공부를 기록하는 공간
[파이썬 주식] 변동성돌파전략 - 6. 종목 개수와 수익률의 관계? 본문
현재 29개의 종목으로 백테스트 및 실전 매매를 진행중이며,
하루 최대 5종목까지 사고있다.
대부분의 날은 5개의 종목을 모두 사고 있지만 아닌날도 대다수다.
1. 라이브러리 임포트
from pandas_datareader import data as pdr
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
import numpy as np
import time
from pykrx import stock
# matplotlib 한글 폰트 출력코드
import matplotlib
from matplotlib import font_manager, rc
import platform
try :
if platform.system() == 'Windows':
# 윈도우인 경우
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
else:
# Mac 인 경우
rc('font', family='AppleGothic')
except :
pass
matplotlib.rcParams['axes.unicode_minus'] = False 2. 종목 불러오기
codes = ['A204320', 'A028050', 'A035150', 'A011210', 'A131390', 'A006360', 'A005070', 'A005380', 'A001510', 'A001140', 'A068270', 'A004020', 'A032560', 'A200130', 'A039490',
'A079430', 'A000990', 'A011790', 'A210980', 'A002840', 'A035510', 'A029460', 'A086280', 'A005940', 'A006800', 'A020760', 'A011760', 'A069260']
codes = [ code[1:] for code in codes ]3. 수익률 함수 만들기
def backtest(code, k, start):
code = str(code)+".KS"
df=pd.DataFrame()
df = pdr.get_data_yahoo(code, start)
df['변동폭'] = df['High']-df['Low']
df['목표가'] = df['Open'] + df['변동폭'].shift(1)*k
df['MA3_yes'] = df.Close.rolling(window=3).mean().shift(1)
df['내일시가'] = df.Open.shift(-1)
cond = ( df['High'] > df['목표가'] ) & ( df['목표가'] > df['MA3_yes'] )
df.loc[cond,'수익률'] = df.loc[cond,'내일시가']/df.loc[cond,'목표가']-0.0032
return df['수익률']
returns = pd.DataFrame()
for code in codes:
df = backtest(code,k=0.5,start='2020-01-01')
returns[code] = df
time.sleep(0.01)
returns.set_index(returns.index.strftime("%Y-%m-%d"),inplace=True)4. 종목별 수익률 데이터프레임에서 종합 데이터프레임 만들기
returns_=pd.DataFrame()
returns_['min']= returns.min(axis=1)
returns_['mean']= returns.mean(axis=1)
returns_['median']= returns.median(axis=1)
returns_['max']= returns.max(axis=1)
returns_['count'] = returns.count(axis=1)
returns_['승패'] = returns_['mean'].map(lambda x:1 if x>1 else 0 )
#returns_['std'] = returns.std(axis=1)5. 시각화
f, ax = plt.subplots(figsize=(10,5))
sns.distplot(returns_['count'], kde=False, bins=10)
plt.title("count")
가로축은 29개 종목 중 하루 단위로 조건(k=0.5 일때, 목표가 > MA3)을 만족하는 경우의 수로 1~20정도로 분포 한다.
지난 1년간 가장 빈도가 많은 것은 종목수가 11~12개가 만족하는 경우이며, 아닐 경우 대다수 10개 이하를 만족한다.
만족하는 종목수(count) 별 평균 수익률 분포 그리기
def dist_plot(col, data, k):
f, ax = plt.subplots(figsize=(10, 5))
cond = (data['count']==k)
sns.distplot(data.loc[cond, col].dropna(), kde=False, bins=10)
plt.title("count : {}".format(k))
plt.show()



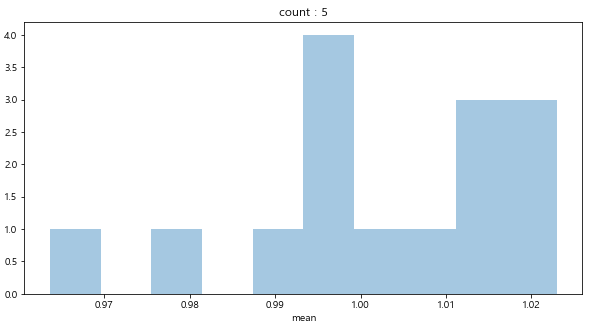

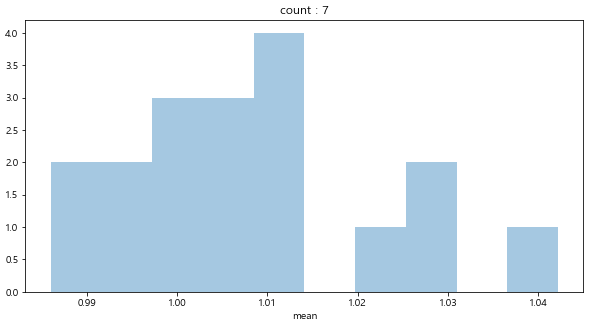










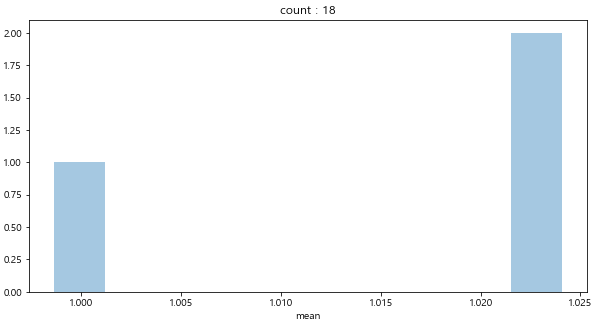


count가 1~2일 경우 손해(mean <1) 보는 경우가 많다. 다만 희한하게도 3인경우는 이득(mean>1)을 보는경우가 더 많다.
count가 4~7까지는 어느정도 손해와 이득을 보는 경우가 혼재한다.
그러나 count가 8 이상인 경우는 대부분 이득을 본다. (그렇지만 이런 경우의 빈도는 보통 1이나 2이다)
하루에 거래하는 종목의 개수의 한도를 늘리는 것은 도움이 될까?
한도 개수만큼 구매 비용을 줄이기 때문에 리스크를 줄이는 효과가 있을 듯 하다.
예를들어 100만원으로 10개 종목을 한도로 정하였고, 한 종목만 조건을 만족하는 날의 경우,
설사 그 하나의 종목이 10% 하락한다고 하더라고 1만원밖에 손해를 보지 않는다.
100 만원 * 1종목/10종목 * 10%하락 = 1만원
거래 종목수를 늘려서 더 분산 투자하는 것이 손실률을 줄일 수 있을 것 같다.
### 수익률과 count 시각화
fig, ax1 = plt.subplots(figsize=(30,8))
returns_['count'][:-1].plot()
ax2 = ax1.twinx()
returns_['mean'][:-1].plot(color='red', ax=ax2,alpha=0.5)
'STOCK > 변동성돌파전략' 카테고리의 다른 글
| [파이썬 주식] 변동성돌파전략 - 8. 실적 검토 (0) | 2021.02.06 |
|---|---|
| [파이썬 주식] 변동성돌파전략 - 7. kospi와 수익률 관계? (0) | 2021.01.30 |
| [파이썬 주식] 변동성돌파전략 - 5.백테스트 결과 시각화 해보기 (0) | 2021.01.25 |
| [파이썬 주식] 변동성돌파전략 - 4. 적정 k값은? (0) | 2021.01.24 |
| [파이썬 주식] 변동성돌파전략 - 3. 종목/조건 3개월 백테스트 (0) | 2021.01.23 |
'STOCK/변동성돌파전략' Related Articles
more




Comments