
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 토익스피킹
- lstm
- PolynomialFeatures
- Quant
- 실기
- backtest
- 데이터분석전문가
- 주식
- 변동성돌파전략
- 볼린저밴드
- 파이썬
- hackerrank
- GridSearchCV
- 백테스트
- 데이터분석
- randomforest
- 파이썬 주식
- 빅데이터분석기사
- ADP
- Crawling
- 파트5
- SQL
- 프로그래머스
- docker
- 비트코인
- 코딩테스트
- TimeSeries
- Python
- Programmers
- sarima
Archives
- Today
- Total
데이터 공부를 기록하는 공간
[multi-classification] forest_cover_type 본문
kaggle > forest cover type
1. 데이터 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
train = pd.read_csv("./forest-cover-type-prediction/train.csv")
test = pd.read_csv("./forest-cover-type-prediction/test.csv")
print(train.shape, test.shape)
train = pd.read_csv("./forest-cover-type-prediction/train.csv")
test = pd.read_csv("./forest-cover-type-prediction/test.csv")
print(train.shape, test.shape)
# feature heatmap
fig, ax = plt.subplots(figsize=(12,12))
sns.heatmap(train.iloc[:,:-1].corr())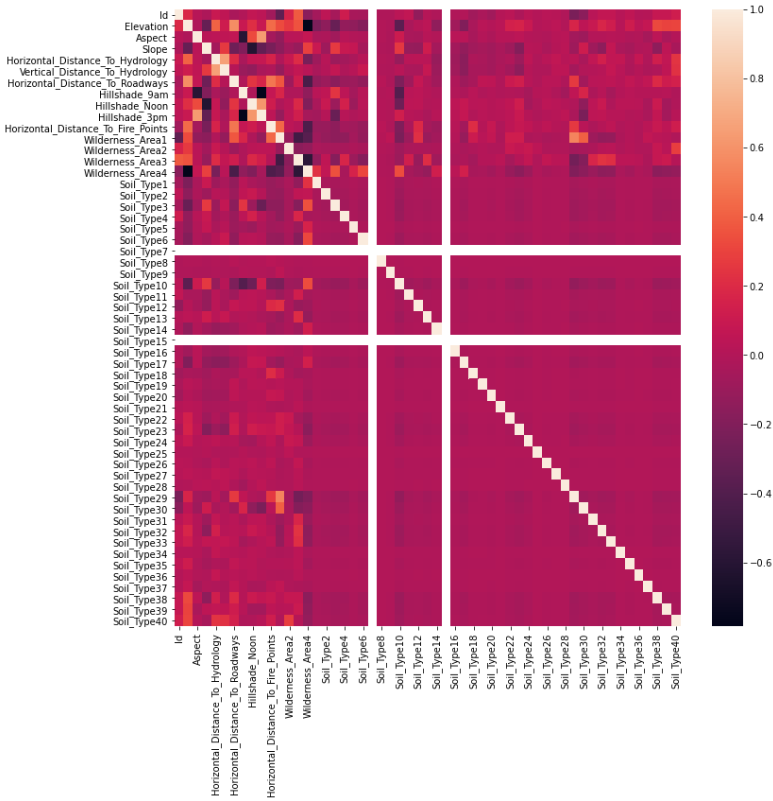
2. 모델링
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from lightgbm import LGBMClassifier
# train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(
train.drop('Cover_Type', axis=1), train['Cover_Type'], test_size=0.3, random_state=17)
#logistic algorithm with pipe
logit = LogisticRegression(C=1, solver='lbfgs', max_iter=500, random_state=17, n_jobs=4, multi_class='multinomial')
logit_pipe = Pipeline([('scaler', StandardScaler()), ('logit', logit)])
logit_pipe.fit(X_train, y_train)
logit_val_pred = logit_pipe.predict(X_valid)
print(accuracy_score(y_valid, logit_val_pred))▶ 0.7039241622574955
#random forest
first_forest = RandomForestClassifier(n_estimators=100, random_state=17, n_jobs=4)
first_forest.fit(X_train, y_train)
forest_val_pred = first_forest.predict(X_valid)
accuracy_score(y_valid, forest_val_pred)▶ 0.8657407407407407
# feature importances
pd.DataFrame(first_forest.feature_importances_,
index=X_train.columns, columns=['Importances']).sort_values(
by='Importances', ascending=False)[:10]
# LGBM
lgb_clf = LGBMClassifier(random_state=17)
lgb_clf.fit(X_train, y_train)
lgb_val_pred = lgb_clf.predict(X_valid)
accuracy_score(y_valid, lgb_val_pred)▶ 0.8725749559082893
3. 하이퍼 파라미터 튜닝
# hyper parameter tuning1
param_grid = {'num_leaves':[7,15,31,63],
'max_depth':[3,4,5,6,-1]}
grid_searcher = GridSearchCV(estimator=lgb_clf, param_grid=param_grid,
cv=5, verbose=1, n_jobs=4)
grid_searcher.fit(X_train, y_train)
grid_searcher.best_params_, grid_searcher.best_score_
# ▶ ({'max_depth': -1, 'num_leaves': 63}, 0.8682917028680418)
accuracy_score(y_valid, grid_searcher.predict(X_valid))
▶ 0.8822751322751323
# hyper parameter tuning2
num_iterations = 200
lgb_clf2 = LGBMClassifier(random_state=17, max_depth=-1, num_leaves=63,
n_estimators=num_iterations, n_jobs=1)
param_grid2 = {"learning_rate" : np.logspace(-3,0,10)}
grid_searcher2 = GridSearchCV(estimator=lgb_clf2, param_grid=param_grid2,
cv=5, verbose=1, n_jobs=4)
grid_searcher2.fit(X_train, y_train)
print(grid_searcher2.best_params_, grid_searcher2.best_score_)
print(accuracy_score(y_valid, grid_searcher2.predict(X_valid)))▶ {'learning_rate': 0.21544346900318823} 0.8747165130954475
▶ 0.8824955908289241
# final lgbm
final_lgb.fit(train.drop('Cover_Type', axis=1), train['Cover_Type'])
lgb_final_pred = final_lgb.predict(test)
pd.DataFrame(final_lgb.feature_importances_,
index=X_train.columns, columns=['Importance']).sort_values(
by='Importance', ascending=False)[:10]
'STUDY > ADP, 빅데이터분석기사' 카테고리의 다른 글
| [classification] titanic (0) | 2021.03.20 |
|---|---|
| [regression] restaurant revenue prediction (0) | 2021.03.20 |
| [regression] house_price_prediction (0) | 2021.03.19 |
| ADP 실기문제 그루핑 (0) | 2021.03.13 |
| ADP 실기 - 문제 정리 (0) | 2021.03.13 |
'STUDY/ADP, 빅데이터분석기사' Related Articles
more



Comments