
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 볼린저밴드
- 파이썬
- 데이터분석전문가
- 코딩테스트
- PolynomialFeatures
- sarima
- 토익스피킹
- backtest
- 빅데이터분석기사
- randomforest
- 주식
- 파트5
- 백테스트
- docker
- Python
- lstm
- Quant
- 데이터분석
- Crawling
- 실기
- TimeSeries
- ADP
- hackerrank
- 비트코인
- SQL
- Programmers
- GridSearchCV
- 프로그래머스
- 파이썬 주식
- 변동성돌파전략
Archives
- Today
- Total
데이터 공부를 기록하는 공간
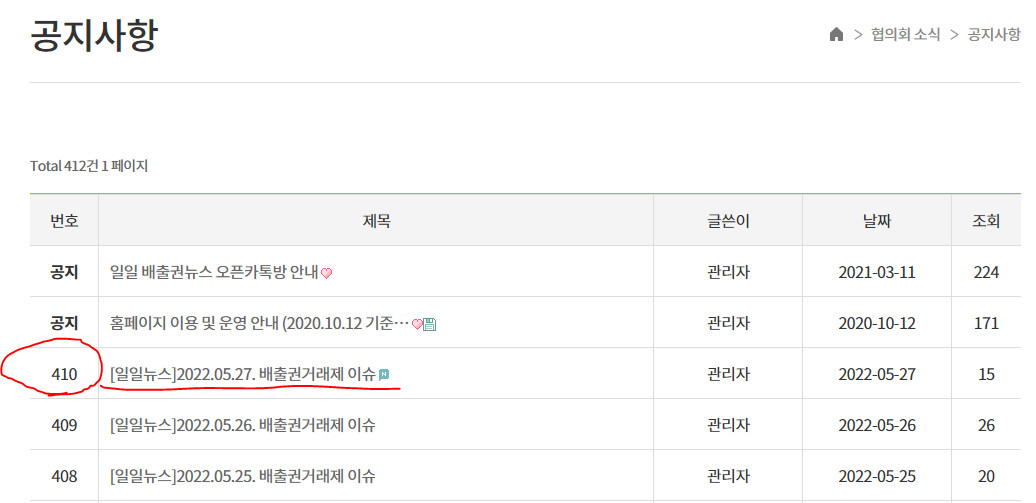
[CRAWLING] beautifulsoup-kema 본문

finding url
417 = 410 + 7
# kema
url = 'http://www.k-ets.or.kr/bbs/board.php?bo_table=s6_1'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
# find 410
for i in soup.find_all('div', class_='div_td col_num'):
temp = i.get_text().strip()
if temp.isdigit():
point = temp
print(point)
breakurl2 = 'http://www.k-ets.or.kr/bbs/board.php?bo_table=s6_1&wr_id={}'.format(int(point)+7)
res2 = requests.get(url2)
soup2 = BeautifulSoup(res2.text, 'html.parser')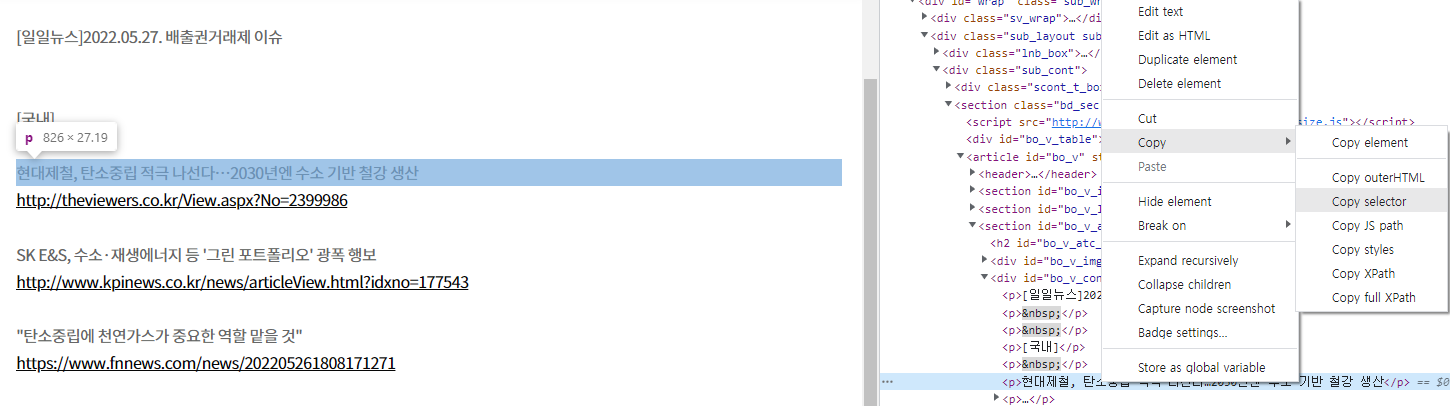
crawling
soup2.select('#bo_v_con')
for i in soup2.select('#bo_v_con')[0].find_all('p'):
print(i.text.strip())
another way
for i in soup2.find_all('p'):
print(i.text.strip())
'STUDY > CRAWLING' 카테고리의 다른 글
| [crawling] requests - 배출권시세 (0) | 2022.06.06 |
|---|---|
| [crawling] requests - krx 시세 가져오기 (0) | 2022.06.06 |
| [CRAWLING] OPENAPI - smp (0) | 2022.05.27 |
'STUDY/CRAWLING' Related Articles
more



Comments