
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 토익스피킹
- Programmers
- hackerrank
- Crawling
- lstm
- 프로그래머스
- Python
- 파이썬 주식
- SQL
- backtest
- 변동성돌파전략
- ADP
- PolynomialFeatures
- sarima
- docker
- 비트코인
- 데이터분석전문가
- randomforest
- 볼린저밴드
- 파이썬
- Quant
- GridSearchCV
- 백테스트
- 코딩테스트
- 빅데이터분석기사
- 실기
- 주식
- TimeSeries
- 데이터분석
- 파트5
Archives
- Today
- Total
데이터 공부를 기록하는 공간
백테스트 - MLP 본문
(참고) 파이썬을 활용한 알고리즘 트레이딩 6장
data = df.copy()
data['return'] = np.log(data['close']/data['close'].shift(1))
data.dropna(inplace=True)
data['direction'] = np.where(data['return']>0, 1, 0)
lags = 5
cols = []
for lag in range(1, lags+1):
col = "lag_{}".format(lag)
data[col] = data['return'].shift(lag)
cols.append(col)
data.dropna(inplace=True)
data
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam, RMSprop
optimizer = Adam(learning_rate=0.0001)
def set_seeds(seed=100):
#random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(100)
set_seeds()
model = Sequential()
model.add(Dense(64, activation='relu',
input_shape=(lags,)))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])
cutoff = '2021-12-31'
training_data = data[data.index<cutoff].copy()
mu, std = training_data.mean(), training_data.std()
training_data_ = (training_data-mu)/std
test_data = data[data.index>=cutoff].copy()
test_data_ = (test_data-mu)/std%%time
model.fit(training_data_[cols], training_data['direction'],
epochs=20, verbose=False,
validation_split=0.2, shuffle=False)res = pd.DataFrame(model.history.history)
res[['accuracy','val_accuracy']].plot(figsize=(10,6), style='--')
model.evaluate(training_data_[cols], training_data['direction'])
cutoff_value = 0.5
pred = np.where(model.predict(training_data_[cols])>cutoff_value, 1,0)
pred[:30].flatten()
# 실제값
data['direction'].value_counts()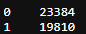
pred.flatten().sum()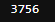
▶ 실제 19810중 3756 번 찾음
# long
training_data['prediction'] = np.where(model.predict(training_data_[cols]) > 0, 1,0)
training_data['strategy'] = training_data['prediction']*training_data['return']
training_data[['return','strategy']].sum().apply(np.exp)
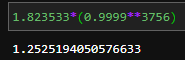
▶ 82% 수익률, 수수료 제외한 것이므로, 수수료 0.01%(0.005%*2, 매수 매도, 슬리피지 고려 x)로 가정시,
1.823533*(0.99990**3756) = 1.2525 > 25% 수익률로 감소 (3756번 매수/매도를 진행)
# long-short
training_data['prediction'] = np.where(model.predict(training_data_[cols]) > 0, 1,-1)
training_data['strategy'] = training_data['prediction']*training_data['return']
training_data[['return','strategy']].sum().apply(np.exp)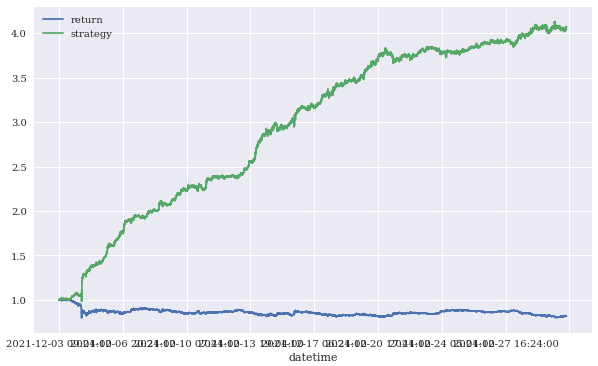
■ 다른 전략을 변수로 추가
data['momentum'] = data['return'].rolling(5).mean().shift(1)
data['volatility'] = data['return'].rolling(20).std().shift(1)
data['distance'] = (data['close']-data['close'].rolling(50).mean()).shift(1)
data.dropna(inplace=True)
cols.extend(['momentum','volatility','distance'])cutoff = '2021-12-31'
training_data = data[data.index<cutoff].copy()
mu, std = training_data.mean(), training_data.std()
training_data_ = (training_data-mu)/std
test_data = data[data.index>=cutoff].copy()
test_data_ = (test_data-mu)/std
set_seeds()
model = Sequential()
model.add(Dense(32, activation='relu',
input_shape=(len(cols),)))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])%%time
model.fit(training_data_[cols], training_data['direction'],
verbose=False,
epochs=25)res = pd.DataFrame(model.history.history)
res[['accuracy']].plot(figsize=(10,6), style='--')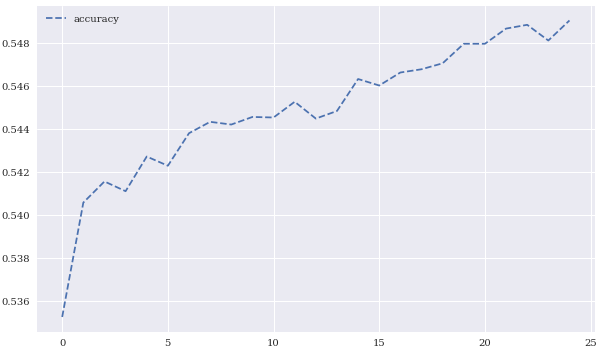
cutoff_value = 0.5
pred = np.where(model.predict(training_data_[cols])>cutoff_value, 1,0)
pred[:30].flatten()
pred.sum()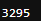
training_data['prediction'] = np.where(pred > 0, 1, 0)
training_data['strategy'] = (training_data['prediction']*
training_data['return'])
training_data[['return','strategy']].sum().apply(np.exp)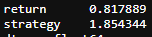
training_data[['return','strategy']].cumsum().apply(np.exp).plot(figsize=(10,6))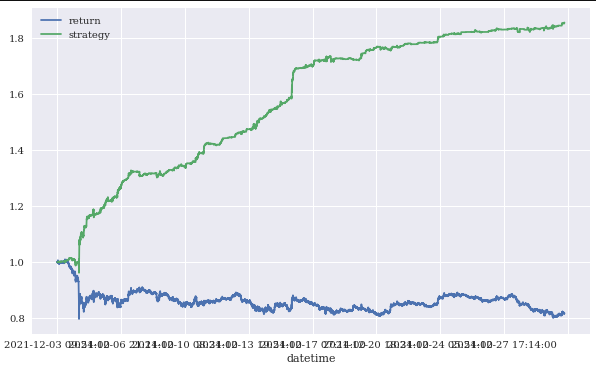
▶ MLP를 활용해서, 보다 좋은 결과를 얻을 수 있었으나, 이건 train data에 대한 결과일 뿐.
해야할 일
- 최적의 hypterparameter 최적화
- 모델 결과에 대해 cutoff_value 최적화
- 모델 평가지표에 accuracy 대신 정밀도(Precision)으로 평가해보기
* 정밀도 : 모델이 True라고 예측한 것중 실제로 True인 정도
* 재현율(recall) : 실제 True인데 모델이 True라고 예측한 정도
- 거래량을 조금 줄여야 할 것으로 보임 (슬리피지 및 수수료 때문에)
> 1분봉 대신 3분봉, 5분봉을 활용?
- 다른 지표와 연결을 추가적으로 함께 검토해야할 듯
'STOCK > 비트코인' 카테고리의 다른 글
| 백테스트 - MLP 5분봉 volume 변수추가 (0) | 2022.01.03 |
|---|---|
| 백테스트 - MLP 5분봉 (0) | 2022.01.03 |
| 백테스트 - logistic regression (0) | 2022.01.03 |
| 백테스트 - 모멘텀 (0) | 2022.01.02 |
| 업비트 API (0) | 2022.01.02 |
'STOCK/비트코인' Related Articles
more




Comments