
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 비트코인
- 데이터분석
- backtest
- 백테스트
- 실기
- Programmers
- sarima
- 토익스피킹
- GridSearchCV
- 주식
- Crawling
- PolynomialFeatures
- TimeSeries
- 파이썬 주식
- SQL
- docker
- ADP
- randomforest
- 코딩테스트
- 데이터분석전문가
- Python
- 파트5
- lstm
- 프로그래머스
- hackerrank
- 파이썬
- 빅데이터분석기사
- Quant
- 변동성돌파전략
- 볼린저밴드
Archives
- Today
- Total
데이터 공부를 기록하는 공간
전력수급 실시간 crawling 본문
http://epsis.kpx.or.kr/epsisnew/
전력수급 > 실시간 전력수급 데이터 화면(아래)를 크롤링

from selenium import webdriver
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
driver = webdriver.Chrome("./chromedriver")
#3초 기다려주기, 웹페이지 로딩까지
driver.implicitly_wait(3)
driver.get("http://epsis.kpx.or.kr/epsisnew/selectEkgeEpsMepRealChart.do?menuId=030300")
soup = BeautifulSoup(driver.page_source, 'html.parser')a = []
for i in soup.find("div", class_='tablewrap').find_all("td"):
print(i.text)
a
idx = []
for i in soup.find("div", class_='tablewrap').find_all("th")[6:]:
idx.append(i.text)
idx
columns = ['공급능력(MW)','현재부하(MW)', '공급예비력(MW)','공급예비율(%)','기온(℃)']
df = pd.DataFrame(np.array(a).reshape(-1,5), columns = columns, index = idx)
df
20분 뒤 다시 실행
driver = webdriver.Chrome("./chromedriver")
driver.implicitly_wait(3)
driver.get("http://epsis.kpx.or.kr/epsisnew/selectEkgeEpsMepRealChart.do?menuId=030300")
soup = BeautifulSoup(driver.page_source, 'html.parser')
a = []
for i in soup.find("div", class_='tablewrap').find_all("td"):
a.append(i.text)
idx = []
for i in soup.find("div", class_='tablewrap').find_all("th")[6:]:
idx.append(i.text)
columns = ['공급능력(MW)','현재부하(MW)', '공급예비력(MW)','공급예비율(%)','기온(℃)']
df_new = pd.DataFrame(np.array(a).reshape(-1,5), columns = columns, index = idx)
df_new

df = pd.concat([df_new, df_1])
df
2021-12-19 18:50 중복으로 중복제거 필요
df = df.loc[~df.index.duplicated(keep='first')]
df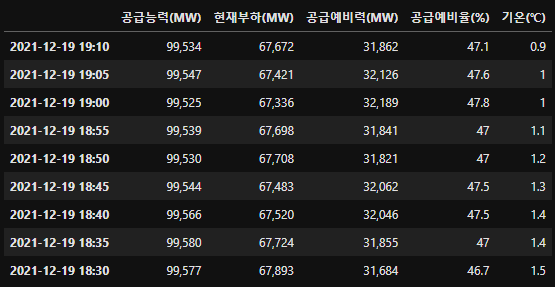
'STUDY > MLOPS' 카테고리의 다른 글
| [crawling] 보도자료 list up (0) | 2022.03.14 |
|---|---|
| [crawling, flask] 프로젝트2 - 뉴스 및 네이버쇼핑 크롤링 페이지 (0) | 2021.12.19 |
| [crawling,flask] 프로젝트 1 - 인기글 불러오는 페이지 만들기 (0) | 2021.12.18 |
| ubuntu에 아나콘다 설치하기 (0) | 2021.12.07 |
| DOCKER 설치 오류 관련 (0) | 2021.12.06 |
'STUDY/MLOPS' Related Articles
more



Comments