STUDY/ADP, 빅데이터분석기사
빅데이터분석기사 실기 - 분류
BOTTLE6
2021. 6. 13. 13:23
XGBOOST로 해보기
# 데이터불러오기
X_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_train.csv",encoding='cp949')
X_test = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_test.csv",encoding='cp949')
y_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/y_train.csv",encoding='cp949')
print(X_train.shape, X_test.shape, y_train.shape)
X_train.set_index("cust_id", inplace=True)
X_test.set_index("cust_id", inplace=True)
y_train.set_index("cust_id", inplace=True)
# 데이터 전처리
print(X_train.shape, X_test.shape, y_train.shape)
## null data 확인
#print(X_train.isnull().sum().sort_values(ascending=False), X_test.isnull().sum().sort_values(ascending=False), y_train.isnull().sum())
X_train.fillna(0, inplace=True)
X_test.fillna(0, inplace=True)
print("NULL Data : " , X_train.isnull().sum().sum(), X_test.isnull().sum().sum(), y_train.isnull().sum().sum())
obj_features = X_train.select_dtypes(include='object').columns.tolist()
num_features = X_train.select_dtypes(exclude='object').columns.tolist()
print(obj_features, num_features)
print("주구매상품 test o , train x : ",[i for i in X_test['주구매상품'].unique().tolist() if i not in X_train['주구매상품'].unique().tolist()])
print("주구매지점 test o , train x : ",[i for i in X_test['주구매지점'].unique().tolist() if i not in X_train['주구매지점'].unique().tolist()])
from sklearn.preprocessing import LabelEncoder
for col in obj_features:
le = LabelEncoder()
le.fit(X_train[col])
X_train[col] = le.transform(X_train[col])
X_test[col] = le.transform(X_test[col])
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import Normalizer #Normarlizer가 제일 좋은듯
from sklearn.preprocessing import StandardScaler
#for col in X_train.columns.tolist(): #obj_features도 모두 minmaxscaling
for col in num_features:
mm = MinMaxScaler()
mm.fit(np.array(X_train[col]).reshape(-1,1))
X_train[col] = mm.transform(np.array(X_train[col]).reshape(-1,1))
X_test[col] = mm.transform(np.array(X_test[col]).reshape(-1,1))
"""
# one-hot encoding
temp = pd.concat([X_train[obj_features], X_test[obj_features]], axis=1)
temp = pd.get_dummies(temp, dtype=np.int64)
train_temp = temp.iloc[:X_train.shape[0],:]
test_temp = temp.iloc[X_train.shape[0]:,:]
X_train = pd.concat([X_train[num_features], train_temp], axis=1)
X_test = pd.concat([X_test[num_features], test_temp], axis=1)
"""
print(X_train.shape, X_test.shape, y_train.shape)
# 데이터 구분, 모델링
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import xgboost as xgb
from sklearn.ensemble import RandomForestClassifier
#model = xgb.XGBClassifier(n_estimators=100, max_depth=3, learning_rate=0.05)
model = RandomForestClassifier(n_estimators=100, max_depth=15, min_samples_leaf=2)
crossval = cross_val_score(model, X_train, y_train, cv=3, scoring='roc_auc', n_jobs=-1)
print("cross val score : ", np.round(crossval.mean()*100,0),"%")
#params = {"n_estimators":[100,300,500], "max_depth":[3,5,10,None], "learning_rate":[0.01, 0.05, 0.1, 0.3]}
#gridsearch = GridSearchCV(model, param_grid=params, cv=5, n_jobs=-1, verbose=1)
#gridsearch.fit(X_train, y_train)
#print(gridsearch.best_estimator_.get_params())

2. label ▶ one-hot encoding, Linear regression,
# 데이터불러오기
X_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_train.csv",encoding='cp949')
X_test = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_test.csv",encoding='cp949')
y_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/y_train.csv",encoding='cp949')
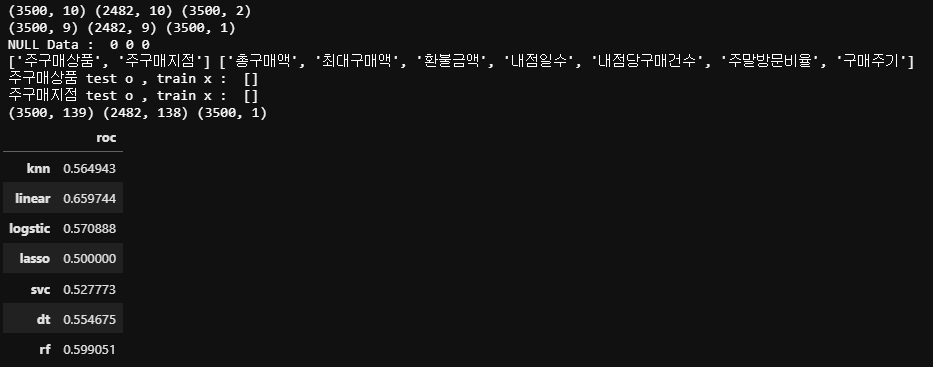
print(X_train.shape, X_test.shape, y_train.shape)
X_train.set_index("cust_id", inplace=True)
X_test.set_index("cust_id", inplace=True)
y_train.set_index("cust_id", inplace=True)
# 데이터 전처리
print(X_train.shape, X_test.shape, y_train.shape)
## null data 확인
#print(X_train.isnull().sum().sort_values(ascending=False), X_test.isnull().sum().sort_values(ascending=False), y_train.isnull().sum())
X_train.fillna(0, inplace=True)
X_test.fillna(0, inplace=True)
print("NULL Data : " , X_train.isnull().sum().sum(), X_test.isnull().sum().sum(), y_train.isnull().sum().sum())
obj_features = X_train.select_dtypes(include='object').columns.tolist()
num_features = X_train.select_dtypes(exclude='object').columns.tolist()
print(obj_features, num_features)
print("주구매상품 test o , train x : ",[i for i in X_test['주구매상품'].unique().tolist() if i not in X_train['주구매상품'].unique().tolist()])
print("주구매지점 test o , train x : ",[i for i in X_test['주구매지점'].unique().tolist() if i not in X_train['주구매지점'].unique().tolist()])
"""
from sklearn.preprocessing import LabelEncoder
for col in obj_features:
le = LabelEncoder()
le.fit(X_train[col])
X_train[col] = le.transform(X_train[col])
X_test[col] = le.transform(X_test[col])
"""
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import Normalizer #Normarlizer가 제일 좋은듯
from sklearn.preprocessing import StandardScaler
#for col in X_train.columns.tolist(): #obj_features도 모두 minmaxscaling
for col in num_features:
mm = MinMaxScaler()
mm.fit(np.array(X_train[col]).reshape(-1,1))
X_train[col] = mm.transform(np.array(X_train[col]).reshape(-1,1))
X_test[col] = mm.transform(np.array(X_test[col]).reshape(-1,1))
# one-hot encoding
temp = pd.concat([X_train[obj_features], X_test[obj_features]], axis=1)
temp = pd.get_dummies(temp, dtype=np.int64)
train_temp = temp.iloc[:X_train.shape[0],:]
test_temp = temp.iloc[X_train.shape[0]:,:]
X_train = pd.concat([X_train[num_features], train_temp], axis=1)
X_test = pd.concat([X_test[num_features], test_temp], axis=1)
print(X_train.shape, X_test.shape, y_train.shape)
# 데이터 구분, 모델링
from sklearn.model_selection import train_test_split
X1, X2, y1, y2 = train_test_split(X_train, y_train, test_size=0.3, shuffle=True, random_state=36)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import Lasso
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
#from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
results = pd.DataFrame(columns=['roc'])
models = {'knn':KNeighborsClassifier(), 'linear':LinearRegression(), 'logstic':LogisticRegression(C=0.5), 'lasso':Lasso(alpha=0.1), 'svc':SVC(C=0.5), "dt":DecisionTreeClassifier(), "rf":RandomForestClassifier()}#, "xgb":XGBClassifier()}
for key, model in models.items():
model.fit(X1, y1)
pred = model.predict_proba(X2)
roc = roc_auc_score(y2, pred)
#print(key, roc)
results.loc[key] = roc
results
from sklearn.model_selection import cross_val_score
model = LinearRegression()
#model = RandomForestClassifier()
crossvalscore = cross_val_score(model, X_train, y_train, cv=5, n_jobs=-1, scoring='roc_auc')
print("cross val score : ", np.round(crossvalscore.mean()*100,0),"%")
from sklearn.model_selection import GridSearchCV
model = LogisticRegression()
param_grids = {"C":[0.1, 0.5, 1, 10]}
gridsearch = GridSearchCV(model, param_grids, cv=5, n_jobs=-1)
gridsearch.fit(X_train, y_train)
gridsearch.best_estimator_
3. clustering을 추가
# 데이터불러오기
X_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_train.csv",encoding='cp949')
X_test = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/X_test.csv",encoding='cp949')
y_train = pd.read_csv("C:/Users/###/Downloads/빅데이터분석기사 실기/[Dataset] 작업형 제2유형/y_train.csv",encoding='cp949')
print(X_train.shape, X_test.shape, y_train.shape)
X_train.set_index("cust_id", inplace=True)
X_test.set_index("cust_id", inplace=True)
y_train.set_index("cust_id", inplace=True)
# 데이터 전처리
print(X_train.shape, X_test.shape, y_train.shape)
## null data 확인
#print(X_train.isnull().sum().sort_values(ascending=False), X_test.isnull().sum().sort_values(ascending=False), y_train.isnull().sum())
X_train.fillna(0, inplace=True)
X_test.fillna(0, inplace=True)
print("NULL Data : " , X_train.isnull().sum().sum(), X_test.isnull().sum().sum(), y_train.isnull().sum().sum())
obj_features = X_train.select_dtypes(include='object').columns.tolist()
num_features = X_train.select_dtypes(exclude='object').columns.tolist()
print(obj_features, num_features)
print("주구매상품 test o , train x : ",[i for i in X_test['주구매상품'].unique().tolist() if i not in X_train['주구매상품'].unique().tolist()])
print("주구매지점 test o , train x : ",[i for i in X_test['주구매지점'].unique().tolist() if i not in X_train['주구매지점'].unique().tolist()])
"""
from sklearn.preprocessing import LabelEncoder
for col in obj_features:
le = LabelEncoder()
le.fit(X_train[col])
X_train[col] = le.transform(X_train[col])
X_test[col] = le.transform(X_test[col])
"""
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import Normalizer #Normarlizer가 제일 좋은듯
from sklearn.preprocessing import StandardScaler
#for col in X_train.columns.tolist(): #obj_features도 모두 minmaxscaling
for col in num_features:
mm = MinMaxScaler()
mm.fit(np.array(X_train[col]).reshape(-1,1))
X_train[col] = mm.transform(np.array(X_train[col]).reshape(-1,1))
X_test[col] = mm.transform(np.array(X_test[col]).reshape(-1,1))
# one-hot encoding
temp = pd.concat([X_train[obj_features], X_test[obj_features]], axis=1)
temp = pd.get_dummies(temp, dtype=np.int64)
train_temp = temp.iloc[:X_train.shape[0],:]
test_temp = temp.iloc[X_train.shape[0]:,:]
X_train = pd.concat([X_train[num_features], train_temp], axis=1)
X_test = pd.concat([X_test[num_features], test_temp], axis=1)
# clustering으로 군집화
from sklearn.cluster import KMeans
km = KMeans(n_clusters=5)
X_train['cluster'] = km.fit_predict(X_train)
print(X_train.shape, X_test.shape, y_train.shape)
# 데이터 구분, 모델링
from sklearn.model_selection import train_test_split
X1, X2, y1, y2 = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, random_state=10)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import Lasso
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
#from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
results = pd.DataFrame(columns=['roc'])
models = {'knn':KNeighborsClassifier(), 'linear':LinearRegression(), 'logstic':LogisticRegression(C=0.5), 'lasso':Lasso(alpha=0.1), 'svc':SVC(C=0.5), "dt":DecisionTreeClassifier(), "rf":RandomForestClassifier()}#, "xgb":XGBClassifier()}
for key, model in models.items():
model.fit(X1, y1)
pred = model.predict_proba(X2)
roc = roc_auc_score(y2, pred)
#print(key, roc)
results.loc[key] = roc
results