STUDY/ADP, 빅데이터분석기사
[regression] house_price_prediction
BOTTLE6
2021. 3. 19. 22:14
1. EDA 및 데이터 전처리
2. 다중공선성 처리
3. Train/Valid/Test set으로 분리하기
4. 교호작용 고려 모델링 및 평가
# library
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# data
train = pd.read_csv("./house-prices-advanced-regression-techniques/train.csv")
test = pd.read_csv("./house-prices-advanced-regression-techniques/test.csv")
# data shape
print(train.shape, test.shape)
# data seperation
target = 'SalePrice'
features = test.columns.tolist()
features.remove('Id')
# target visulaization
train[target].plot.hist(bins=100)
1. EDA 및 데이터 전처리
# check null data
columns_withnull = train.columns[train.isnull().sum()!=0].tolist()
print(train.isnull().sum().sort_values(ascending=False).head(20))
#remove features that have over 1000 null datas
features.remove('PoolQC')
features.remove('MiscFeature')
features.remove('Alley')
features.remove('Fence')
#feature seperations
category_f = train[features].select_dtypes(include='object').columns.tolist()
num_f = train[features].select_dtypes(exclude='object').columns.tolist()
print("category_f 개수 : ", len(category_f))
print("num_f 개수 : ", len(num_f))
import warnings
warnings.filterwarnings('ignore')
# show numeric_features
for col in num_f:
train[col].fillna(train[col].mean(),inplace=True) # handling null data
fig, ax = plt.subplots(figsize=(6,2))
sns.distplot(train[col])
ax.set_title("{}".format(col))
# another way to show numeric_features
'''
import time
tic = time.time()
f = pd.melt(train, value_vars = num_f)
g = sns.FacetGrid(f, col='variable', col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
print(time.time()-tic, "seconds")
'''
# show category_features
for col in category_f:
train[col].fillna("Unknown",inplace=True) # handling null data
print('-'*50)
print("<< " + str(col) + " >>")
print(train[col].value_counts())
# show category_features by boxplot
for c in category_f:
train[c] = train[c].astype("category")
if train[c].isnull().any():
train[c] = train[c].cat.add_categories(['MISSING'])
train[c] = train[c].fillna("MISSING") # handling null data
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x = plt.xticks(rotation=90)
f = pd.melt(train, id_vars = ['SalePrice'], value_vars = category_f)
g = sns.FacetGrid(f, col='variable', col_wrap = 2, sharex=False, sharey=False)
g = g.map(boxplot, "value", "SalePrice")
# hanling test data's null data
for col in category_f:
test[col].fillna("Unknown",inplace=True)
for col in num_f:
test[col].fillna(train[col].mean(),inplace=True)
print("Skewnews :",train[target].skew())
print("Kurtosis :",train[target].kurt())2. 수치형 데이터로 다중선형회귀 및 다중공선성 제거
import statsmodels.api as sm
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
train[num_f], train['SalePrice'], test_size=0.3, random_state=24)
x_data = X_train
target = y_train
x_data1 = sm.add_constant(x_data, has_constant="add")
x_data1
from sklearn.metrics import mean_squared_error
#modeling
multi_model = sm.OLS(target, x_data1)
fitted_multi_model= multi_model.fit()
x_test1 = sm.add_constant(X_test, has_constant="add")
print(mean_squared_error(y_test, fitted_multi_model.predict(x_test1)))
fitted_multi_model.summary()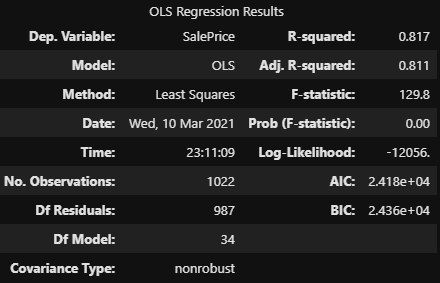
# Check multicollinearity
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif['VIF Factor'] = [variance_inflation_factor(x_data1.values, i)
for i in range(x_data1.shape[1])]
vif['features'] = x_data1.columns
# remove
vif.sort_values(by='VIF Factor', ascending=False)
ex_columns = vif.sort_values(ascending=False, by="VIF Factor")[:8]['features'].values.tolist()
# data2 is data1's copy that exclude features whose vif factor is over 10
x_data2 = x_data1.copy().drop(columns=ex_columns,axis=1)
x_test2 = x_test1.copy().drop(columns=ex_columns,axis=1)
x_data2.columns
multi_model2 = sm.OLS(target, x_data2)
fitted_multi_model2 = multi_model2.fit()
print(mean_squared_error(y_test, fitted_multi_model2.predict(x_test2)))
fitted_multi_model2.summary()
▶ AIC가 24180 → 24230으로 개선됐다.
# coef p_value > 0.05인 features 제거
ex_columns2 = ['LotFrontage','BsmtHalfBath','GarageYrBlt',
'OpenPorchSF','EnclosedPorch','3SsnPorch','PoolArea','MiscVal','MoSold','YrSold']
x_data3 = x_data2.copy().drop(columns=ex_columns2,axis=1)
x_test3 = x_test2.copy().drop(columns=ex_columns2,axis=1)
multi_model3 = sm.OLS(target, x_data3)
fitted_multi_model3 = multi_model3.fit()
print(mean_squared_error(y_test, fitted_multi_model3.predict(x_test3)))
fitted_multi_model3.summary()
sns.heatmap(x_data3.corr(),cmap='Blues')
x_data4 = x_data3.copy().drop(columns=['GarageArea','YearRemodAdd','TotRmsAbvGrd'],axis=1)
x_test4 = x_test3.copy().drop(columns=['GarageArea','YearRemodAdd','TotRmsAbvGrd'],axis=1)
multi_model4 = sm.OLS(target, x_data4)
fitted_multi_model4 = multi_model4.fit()
print(mean_squared_error(y_test, fitted_multi_model4.predict(x_test4)))
fitted_multi_model4.summary()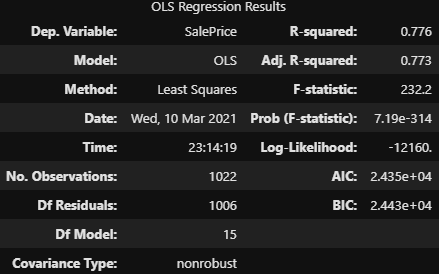
# train_valid_test_split
num_f= x_data4.columns.tolist()[1:]
features = num_f + category_f
from sklearn.model_selection import train_test_split
X_train, X_valtest, y_train, y_valtest = train_test_split(train[features],train['SalePrice'], test_size=0.4, random_state=0)
X_valid, X_test, y_valid, y_test = train_test_split(X_valtest, y_valtest, test_size=0.33, random_state=0)
print(X_train.shape, X_valid.shape, X_test.shape)
print(y_train.shape, y_valid.shape, y_test.shape)
#visualizaion of target
fig, axes = plt.subplots(1,3, figsize=(12,4))
datas = [y_train, y_valid, y_test]
for data, ax in zip(datas, axes):
sns.kdeplot(data, label='{}'.format(data),ax=ax)
#visualization of features
for col in num_f:
datas = [X_train, X_valid, X_test]
fig, axes = plt.subplots(1,3, figsize=(12,4))
for data, ax in zip(datas, axes):
sns.kdeplot(data[col], label='{}'.format(data),ax=ax) # ohehotencoding
df = pd.concat([X_train, X_valid, X_test],axis=0)
df = pd.get_dummies(df)
X_train_trans = df.iloc[0:X_train.shape[0]]
X_valid_trans = df.iloc[X_train.shape[0]:X_train.shape[0]+X_valid.shape[0]]
X_test_trans = df.iloc[X_train.shape[0]+X_valid.shape[0]:]
# polynomialfeatures
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2).fit(X_train_trans)
X_train_poly = poly.transform(X_train_trans)
X_valid_poly = poly.transform(X_valid_trans)
X_test_poly = poly.transform(X_test_trans)
print("X_train_poly.shape: ", X_train_poly.shape)
print("X_valid_poly.shape: ", X_valid_poly.shape)
print("X_test_poly.shape: ", X_test_poly.shape)
dd = pd.DataFrame(X_train_poly)
dd.columns=poly.get_feature_names()
ddfrom sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train_trans, y_train)
lr_poly = LinearRegression()
lr_poly.fit(X_train_poly, y_train)
print("train score : {:.2f}".format(lr.score(X_train_trans, y_train)))
print("valid score : {:.2f}".format(lr.score(X_valid_trans, y_valid)))
print("poly train score : {:.2f}".format(lr_poly.score(X_train_poly, y_train)))
print("poly valid score : {:.2f}".format(lr_poly.score(X_valid_poly, y_valid)))
from sklearn.svm import SVC
svm = SVC()
svm.fit(X_train_trans, y_train)
svm_poly = SVC()
svm_poly.fit(X_train_poly, y_train)
print("train score : {:.2f}".format(svm.score(X_train_trans, y_train)))
print("valid score : {:.2f}".format(svm.score(X_valid_trans, y_valid)))
print("poly train score : {:.2f}".format(svm_poly.score(X_train_poly, y_train)))
print("poly valid score : {:.2f}".format(svm_poly.score(X_valid_poly, y_valid)))
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_train_trans, y_train)
rf_poly = RandomForestRegressor()
rf_poly.fit(X_train_poly, y_train)
print("train score : {:.2f}".format(rf.score(X_train_trans, y_train)))
print("valid score : {:.2f}".format(rf.score(X_valid_trans, y_valid)))
print("poly train score : {:.2f}".format(rf_poly.score(X_train_poly, y_train)))
print("poly valid score : {:.2f}".format(rf_poly.score(X_valid_poly, y_valid)))
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X_train2=X_train.copy()
X_valid2=X_valid.copy()
X_train2[category_f] = X_train2[category_f].apply(le.fit_transform)
X_valid2[category_f] = X_valid2[category_f].apply(le.fit_transform)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train2, y_train)
print("train score : {:.2f}".format(lr.score(X_train2, y_train)))
print("valid score : {:.2f}".format(lr.score(X_valid2, y_valid)))
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_train2, y_train)
print("train score : {:.2f}".format(rf.score(X_train2, y_train)))
print("valid score : {:.2f}".format(rf.score(X_valid2, y_valid)))
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=10)
lasso.fit(X_train2, y_train)
print("train score : {:.2f}".format(lasso.score(X_train2, y_train)))
print("valid score : {:.2f}".format(lasso.score(X_valid2, y_valid)))
from sklearn.metrics import mean_squared_error
def MAPE(y_test, y_pred):
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
from sklearn.metrics import r2_score
mae = mean_squared_error(y_valid, rf.predict(X_valid_trans))
mape = MAPE(y_valid, rf.predict(X_valid_trans))
r2 = r2_score(y_valid, rf.predict(X_valid_trans))
print(mae, mape, r2)